SAP Data Services (BODS) est un outil ETL historique et incontournable dans l’écosystème SAP. Solide, éprouvé et activement maintenu, il continue d’accompagner de nombreux projets d’intégration de données grâce à sa richesse fonctionnelle, ses connecteurs modernes, et sa parfaite intégration avec les environnements SAP et non-SAP.
Parmi ses atouts clés, on retrouve un moteur de traitement hybride, capable d’exploiter la puissance des bases de données via le Push Down SQL, pour des performances optimales et un traitement distribué intelligent.
Comprendre le moteur hybride : quand SAP BODS adopte l’ELT
Dans certains cas, un traitement peut s’avérer très long à exécuter, et en consultant la console, on remarque souvent que le nombre de lignes traitées est bien plus élevé que prévu. Cela signifie que la puissance du moteur hybride n’est pas pleinement exploitée, et que les performances pourraient être largement améliorées en optimisant la manière dont les données sont filtrées et transformées.
C’est là qu’intervient le moteur hybride de SAP Data Services. Son objectif ? Adopter une logique ELT intelligente : charger les données, mais surtout exécuter les transformations directement dans la base de données quand c’est possible, grâce au Push Down SQL. Cette approche permet de réduire la charge mémoire, d’accélérer les traitements et d’optimiser les performances globales du flux.
Il existe plusieurs méthodes pour arriver à utiliser SAP BODS comme un ELT. Dans cet article, nous allons faire un focus sur la méthode du push down simple.
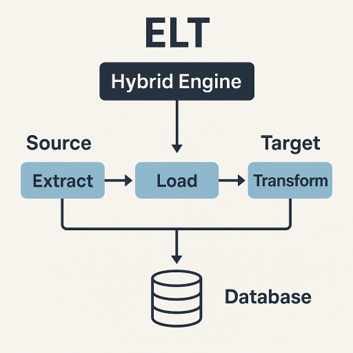
Mettre en place le Push Down SQL dans SAP Data Services
Tirer parti du moteur hybride de SAP Data Services repose avant tout sur la capacité à structurer intelligemment ses flux de données. Le pushdown permet à BODS de déléguer les traitements directement à la base de données, mais il est nécessaire de s’astreindre lors du développement à certaines règles : sources et cibles relationnelles compatibles, transformations simples (jointures, filtres, projections) et équivalence des fonctions BODS avec les expressions SQL natives.
Mais au-delà des critères techniques, la qualité de conception du job est déterminante. Un flux bien structuré, linéaire, sans transformations inutiles ni surcharges intermédiaires, favorisera naturellement l’activation du pushdown.
Lorsque les transformations deviennent plus avancées ou que le pushdown ne s’active pas automatiquement, il est possible de recourir à des méthodes complémentaires pour en faciliter l’activation :
- Segmenter les flux : scinder un flux complexe en plusieurs étapes simples, chacune est optimisée pour le pushdown.
- Privilégier les opérations natives de la base de données : remplacer certaines fonctions BODS par des expressions SQL explicites à l’aide de la fonction pushdown_sql(), ou déléguer les transformations à des fonctions directement exécutées dans la base.
- Analyser le SQL généré dans la vue de suivi (Trace SQL) pour diagnostiquer ce qui empêche l’exécution côté base et adapter le design en conséquence.

Figure 1 : Fenêtre qui montre le SQL généré dans un Dataflow (Source : SAP)
Conclusion
Le moteur hybride de SAP Data Services, et plus particulièrement l’approche Push Down SQL, représente un levier puissant pour optimiser les performances des projets d’intégration de données.
Un flux bien structuré, allégé et conçu en adéquation avec les capacités SQL de la base de données cible favorisera naturellement l’activation du pushdown.
Cependant, une attention particulière doit être portée à la conception des jobs.
Lorsque le pushdown ne peut être pleinement appliqué, il est essentiel d’adapter au mieux les flux afin de transférer un maximum de charge de traitement vers la base de données.
En savoir + sur l’auteur
Cet article a été rédigé par Julia Nadal Teruel (consultante Data chez Seenovate).